In this lab, you will implement a parallel version of the Barnes-Hut algorithm for solving n-body problems. The efficiency of your code will be compared to a reference implementation to help determine your grade.
Begin by obtaining the starter code from the github repository.
git clone https://github.gatech.edu/sb300/oms-hpc-lab2.git
Note that this is the GT github server, so you will need to authenticate with your GT credentials.
Optionally, you may choose use a git hosting service for your code. As always, please do not make your repository public on Github or another git hosting service. Anyone will be able to see it. If you feel the need to use a hosting service for your project, please keep your repository private. Your GT account allows you to create free private repositories on the GT github server.
In classical mechanics, the n-body problem consists of predicting the motion of celestial objects interacting through gravity. That is, given the instantaneous positions and velocities of a group of objects at a given time, predict the gravitational forces and use these to predict the position and velocities for all future times.
In a computational approach to making these predictions, the forces at a given time are calculated, and then numerical integration is used to predict the positions and velocities a short time in the future. Repeating this process makes it possible to generate accurate predictions for celestial motion far into the future even when closed-form solutions are not possible.
In the first part of the lab, you are invited to explore various data sets and visualization techniques for this N-body problem. The repository contains a complete, though woefully slow, implementation. Later in the lab, you will work to improve its performance.
-
An instance of the Body class represents one of the
$n$ bodies. It stores the body's position, velocity, and it provides functions for exerting gravitational forces and performing leapfrog integration given forces on the object. -
The ForceNaive class implements the abstract class ForceCalculator. It takes an array of bodies, say
$B$ as an argument to its constructor. The operator() then takes a body as an argument and applies the gravitational forces from the given set of bodies$B$ . -
UniverseState is a convenience class that contains an array of
$n$ bodies, a time value, and operations for file I/O. -
The Integrator class handles the process of alternately computing forces and integrating positions. After each time step it calls a user-defined callback.
-
The python files barneshut_convert.py and nbody_convert.py convert data from file formats used in a couple of labs from Princeton University into the UniverseState format. You can find files with a small number of bodies here and those with a large number of bodies here.
-
The main file nbody.cc accepts a file containing the initial state as a command line argument, and it outputs as csv file representing the universe state over time.
-
The file visualize.py uses python's matplotlib and pandas libraries to read the data and produce a visualization.
To illustrate the usage of this code, we'll visualize the so-called spiral system. You should first acquire the data by downloading spiral.txt. Then run
python nbody_convert spiral.txt > spiral.us
to convert the file into the UniverseState format. Then compile the nbody main file with
make nbody
and run it with
./nbody -f spiral.us -n 50000 -s 0.01 -r 500 > spiral.csv
Finally, you can visualize the results with
python visualize.py spiral.csv
There are no deliverables for this portion of the lab, but you are encouraged to explore, share tips on things like appropriate time step, share results, and share code for improved visualizations.
The 'naive' computational approach to the n-body problem computes the gravitational force induced by every body to every other body. This results in
The central idea is grouping together bodies that are sufficiently close to each other and sufficiently far from the force calculation point, and approximating the group of bodies as one body with the total group mass located at the group center of mass. 'Sufficiently close' and 'sufficiently far' are defined by a simulation parameter called the multipole acceptance criterion (MAC), usually denoted by

Generally, there is a tradeoff between accuracy and speedup. The lower the MAC, the more accurate but more expensive the computation, because only smaller groups (and hence a greater number of total groups) can be used in the approximation.
To find suitable sets of bodies to group together, a Quadtree data structure is used. This approach recursively divides square regions of
In calculating the force on a particular body, the bodies within a square are grouped together, and if approximating these bodies as a single body meets the MAC, the approximation is used. Otherwise, the contributions from the four sub-squares are summed together.
For 3D data, there is the analogous octree data structure.
Your task for this part of the lab is to implement the Barnes-Hut approximation with a quadtree in the files ForceBarnesHut.hh and ForceBarnesHut.cc. Your ForceBarnesHut class should inherit from ForceCalculator and define the operator () so that it can be used in place of the ForceNaive class. You should construct the quadtree in the constructor and then use it to quickly compute the forces in the () operator member function. The MAC parameter is specified as the variable
Copy-paste your code into the Udacity site at https://www.udacity.com/course/viewer#!/c-ud281/l-4989478591/m-5034784177. The TAs will evaluate the performance of you code after the submission deadline.
What could be faster than the Barnes-Hut approximation? A parallel version, of course! And, indeed, creating a parallel implementation of the Barnes-Hut algorithm is the next part of the lab.
Given the quadtree, parallelizing the force calculation is a simple parallel loop. Parallelizing the construction of the tree, however, is a little more challenging. At first, the tree construction may seem like a curious thing to optimize. In the N-body simulations that you will have done, the dominant part of the computation was the computation of the forces after the construction of the tree. As the number of bodies grows, however, the share of computational time due to the construction increases. In addition, for other applications it may be important to compute the gravitational effect of a large number of bodies, not on each other, but on a smaller set of bodies, perhaps even in real-time. The real-time nature of the problem makes a fast Barnes-Hut approximation necessary, and it would be nice to compute the quadtree quickly so as to be sure to have the tree ready when needed.
Unfortunately, building a quadtree in parallel is not merely a matter of using a parallel for loop. Simply dividing the points among the cores would have them all attempting to modify the same quadtree creating locking or contention problems. One could have each core build its own quadtree, but that approach leaves the problem of merging the tree together, and it's not clear why merging the trees should be much faster than constructing them in a serial fashion.
The key to fast merging of the trees is to avoid having them overlap. If a subtree is present in one tree but entirely absent in an another, then the subtree can be added simply by marking it as a child of the appropriate node. We want to have as much of the merge happen in this way as possible. To achieve this, we use a MortonKey ordering of the bodies.
Morton order is a space-filling curve that follows a 'Z' or 'N' pattern microscopically and macroscopically. This order helps us construct our quadtree efficiently. In our code, and as is common, the pattern has the shape of an 'Z'.
Consider the following image where points reside at each integral coordinate and are ordered in a Morton order starting from (7,7). The curve shape is that of a 'Z'.
![Morton order] (https://upload.wikimedia.org/wikipedia/commons/thumb/c/c6/Morton_scan_order_8%C3%978.svg/240px-Morton_scan_order_8%C3%978.svg.png)
You will notice that curves between individual points have a 'Z', but also the pattern between square regions of points are also 'Z'-shaped. The four quadrants of the whole diagram go bottom-right, bottom-left, top-right, then top-left.
We can discover the Morton order by forming Morton 'keys' associated with each point, and then sorting these keys. Each key can be determined by taking integer representations of the x and y coordinates, and interleaving the bits of these integer representations. The exact values of the integer representations do not really matter, just their relative values to the other points in the domain. If our integer representations of x and y for a particular point are 10001 and 01110, respectively, then with interleaving we get the Morton key of 0110101001. Bit i of the x integer and bit i of the y integer form pair i in the Morton key.
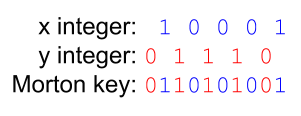
{kind=link}
After sorting the Morton keys, the points (quadtree leaves) are in the order they would appear in the quadtree.
Using the ideas above, complete the implementation of the MortonKeyCalculator class in the files MortonKeyCalculator.cc and MortonKeyCalculator.hh. You should make your implementation parallel. Thankfully, gcc makes this easy with its builtin parallel mode. You should use the method of "Using Specific Parallel Components." The main file mortonsort.cc may be useful for debugging.
Copy-paste your code into the Udacity site at https://www.udacity.com/course/viewer#!/c-ud281/l-4989478591/m-5071434974. The TAs will evaluate the performance of your code after the submission deadline.
As explained above, once the bodies are sorted, the sequence can broken down into consecutive chunks, and each chunk assigned to its own core. If your serial implementation allocates nodes for the quadtree as they are needed, you may want to consider pre-allocating them for your parallel implementation. Because the address space is shared among the several worker threads, memory allocation can be a bottleneck. Regardless of your choice, the sorting by Morton keys will ensure that the resulting trees will have small overlap and can be merged quickly.
Employ this strategy in an updated implementation of the ForceBarnesHut class. If you wish to use the MortonKeyCalculator you implement previously, you will have to include its source in these files. Please submit your code to https://www.udacity.com/course/viewer#!/c-ud281/l-4989478591/m-5059363626.
After successfully completing this lab, you will have solid code base that will allow you to quickly approximate the net forces exerted by n bodies on an arbitrary mass in space. This will allow you to quickly solve the n-body problem for every large instances, and your implementation will be parallel-friendly allowing it benefit where multiple processors are available.