Step
When a step is placed in a transformation, it passes each incoming row to the ruby script as a ruby hash indexed by field name. It is available as the global variable $row.
The script is expected to evaluate to one of the following:
| Result | Effect |
|---|---|
| nil | No output row is produced. |
| hash | A single output row is produced. The hash represents fields to be placed in the output row, and should contain keys for all fields specified in the step's Output Fields configuration. |
| array | The array represents a sequence of rows to produce. Hash elements generate output rows. Nil elements are skipped. |
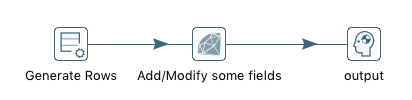
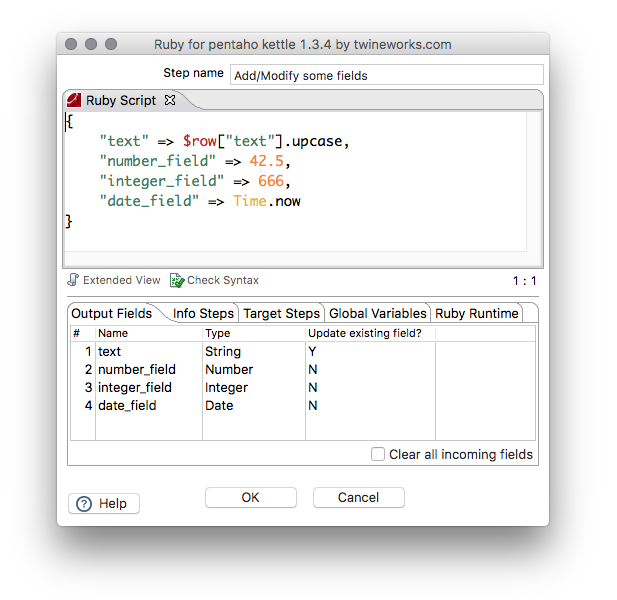
The Output Fields tab defines which fields from a row hash are passed into the row stream.
The following script converts the existing field text to upper case, and adds some new fields to the row stream. Please note how the output fields configuration matches the keys of the resulting hash.
If a ruby step is placed at the beginning of a transformation path, in other words when it does not have any input steps connected to it, it executes the contained script once. The $row variable is nil in this case.
The step can generate rows by evaluating to an array of hashes or writing to the output stream manually.
Incoming row fields are are converted to ruby data types as follows:
| Kettle type | Ruby type |
|---|---|
| String | String |
| Boolean | TrueClass or FalseClass |
| Integer | Fixnum |
| Number | Float |
| BigNumber | BigDecimal |
| Date | Time |
| Timestamp | Time |
| Internet Address | IPAddr |
| Binary | Array of Fixnum (Bytes) |
| Serializable | Adapted Java Class or one of the above if convertible |
When the step converts ruby values to kettle fields, the following mapping takes place:
| Kettle field type | Expected ruby type |
|---|---|
| String | String, or anything that responds to to_s. |
| Boolean | Any value, coerced to boolean as per ruby semantics. |
| Integer | Fixnum, or anything that responds to to_i. |
| Number | Number, or anything that responds to to_f. |
| BigNumber | Float, BigDecimal, or anything that has a string representation that parses as a decimal number. |
| Date | Time, or a Fixnum interpreted as millis since epoch. |
| Timestamp | Time, or a Fixnum interpreted as millis since epoch. |
| Internet Address | IPAddr, or anything that responds to to_i . The 4 least significant bytes of the integer are interpreted as an IP address. |
| Binary | Array of numeric byte values. |
| Serializable | Anything that responds to dump and returns a string. The result is placed into a serializable Object containing that string. |
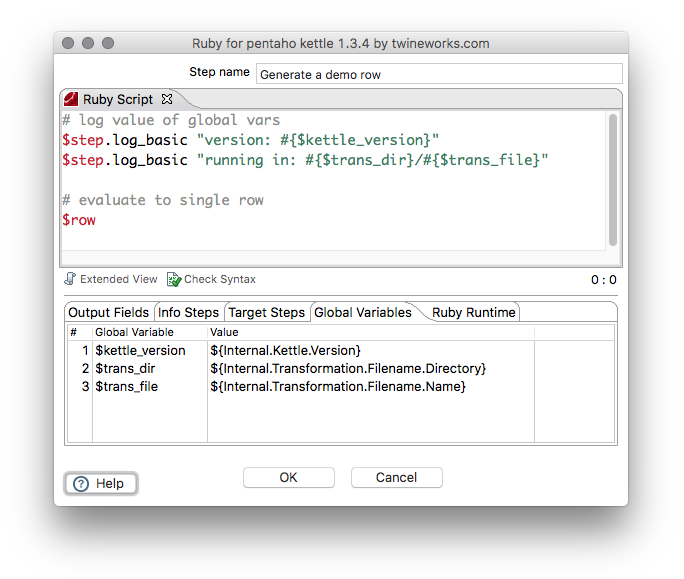
The Global Variables tab allows defining additional global variables placed in scope of the script. The configured values are strings, and they interpolate kettle variables, so it is a convenient way to gain access to commonly needed runtime information like ${Internal.Transformation.Filename.Directory}.
The following example creates global ruby variables populated with kettle variable values. Please note that the variable definitions include a leading $ in the variable name.
The step makes the kettle step object avaiable as $step. You can use the following methods to interact with the kettle log:
| log level | check if log level set | write log message at level |
|---|---|---|
| basic | $step.is_basic |
$step.log_basic |
| error | $step.is_error |
$step.log_error |
| debug | $step.is_debug |
$step.log_debug |
| minimal | $step.is_minimal |
$step.log_minimal |
| detailed | $step.is_detailed |
$step.log_detailed |
| row level | $step.is_row_level |
$step.log_rowlevel |
See calling Java and the kettle step API for background on how you can call into other kettle APIs.
The ruby step is implemented using JRuby, which offers convenient and easy to use Java interop. Therefore your ruby scripts can easily reference existing Java classes and methods, and even load jar files from the file system.
The following script calls java.util.UUID.randomUUID() to generate some random ids.
java_import java.util.UUID
{
"uuid" => UUID::randomUUID().to_s.upcase
}The following script loads an example jar file /step/sample_files/saying-goodbye.jar, instantiates a class from the jar, and places the result of a call to say() into every processed row.
require File.join([$step.plugin_dir, "step", "sample_files", "saying-goodbye.jar"])
# use an instance of GoodBye to tell the farewells
farewells ||= org.typeexit.GoodBye.new
# evaluate to a nice farewell row
{
"farewell" => farewells.say
}The step makes the input steam available as $input . If you'd like to read rows from the input stream, you can call $input.read or $input.read_all.
$input.read() reads a single row from the input stream and returns it as a hash indexed by field name. It returns nil if there are no more rows in the input stream.
$input.read(n) reads n rows from the input stream and returns them in an array. If the input stream has less than n rows, it returns a smaller array. If the input stream does not have any more rows, it returns nil.
$input.read_all() returns all rows from the input stream in an array. It returns an empty array if there are no rows in the input stream.
Sample invocations
# read the next row, check for nil to determine end of stream
successor = $input.read()
# read the next 3 rows, and place into a group with the row passed into the script
# effectively processing 4 rows at a time.
group = [$row] + $input.read(3)
# read everything, remember to include $row, which kettle already passed into the script
all_rows = [$row]+$input.read_all()If you'd like to read rows from specific info steps, you need to first connect all info steps to your ruby step. Then assign tags to each info step on the Info Steps tab. The info steps will be known by the tag you assign to them in the script. They $info_steps hash, indexed by tag, allows you to read from the specific steps. If you tag an info step with "foo", you can read rows from it by calling $info_steps["foo"].read or $info_steps["foo"].read_all just like from the input stream.
Important If you mix normal input steps and info steps connecting to your script step, all rows from the info steps will be loaded into memory before step execution. This happens transparently in the background and is due to a limitation of the Kettle API. The "Stream Lookup" step in kettle is an example for this setup. Should you have a lot of rows provided by your info steps, you should make all input steps info steps. If all incoming steps are info steps, the above limitation does not apply. In this case the rows will be loaded when needed. The "Merge Join" step in kettle is an example for this setup.
The step makes the output stream available as $output. If you'd like to generate a row manually during script execution, you can do so by calling $output.write(out) or use the the << alias: $output << out.
The out argument may be:
| out | effect |
|---|---|
| nil | Nothing is written. |
| a hash | A single row is written, the keys are interpreted as field names as usual. |
| an array | Every entry is required to be a hash or nil. Hashes are written as rows, nil values are skipped. |
Sample invocations:
# writes nothing (NOP)
$output.write nil
# writes a row with all fields set to null
$output.write {}
# writes a row with field "num" set to 42
$output.write {"num" => 42}
# writes two rows with the field "num" set to 42 and 92 respectively.
$output.write [{"num" => 42}, {"num" => 92}]If you'd like to send output rows to specific steps, you can do so by using target steps. This works similarly to the kettle "switch/case" step. First connect your ruby step to all possible output steps. Next open the "Target Steps" tab of the ruby step and assign a tag to each target step. The tag is the name by which your script can refer to a particular target step.
The target steps are made available in the $target_steps hash, indexed by the tag name you assigned to each target step. Assuming there's a target step tagged "foo", you can send rows to it by calling
$target_steps["foo"].write(out) or using the << alias $target_steps["foo"] << out, just like to the the output stream.
To use Kettle's error handling feature you need to define an error output step the usual way: connect the ruby step to the step that should receive rejected rows, then right click the ruby step and select "define error handling". Specify the error fields as you like them.
The error stream is made available as $error. Call $error.write(err) or the alias $error << err to send an error row hash to the error step. Be sure to include the error fields you specified in the error handling dialog. You may also pass entire arrays of rows, just like with any other output stream.
To add more script tabs, right click the script tabs bar and choose "Add Script" from the context menu.
Each script tab has a type associated with it. New tabs are always created as "Lib Scripts". Types can be assigned by selecting the tab in question, right clicking it and choosing another type from the list.

Row scripts are executed once for each input row. If the ruby step has no input steps, the script is executed just once. Each ruby step must have exactly one script with this type. If you assign this type to a script, any existing row script will turn into a lib script automatically.
Start scripts are executed once before any other script tab runs. They are guaranteed to execute, even if there are no input rows. Start scripts are used to set up complex objects or to allocate resources like database connections or file handles that are used by the row script for row processing. There may be only one start script defined in any ruby step.
End scripts are executed after the last row has been processed by the row script. They are guaranteed to execute even if there are no input rows. End scripts are usually used to release resources acquired by a start script, or to generate summary rows by manually writing to the output stream. There may be only one end script defined in any ruby step.
Lib scripts are not executed unless specifically included by some other script.
All script tabs are made available as the $tabs hash. It is indexed by tab title. Script tabs can be included in two different ways.
Including a script once
A call to $tabs["My Lib Script"].require() causes the script tab named "My Lib Script" to be evaluated once. Subsequent calls to require() have no effect.
Including a script multiple times
A call to $tabs["My Lib Script"].load() causes the script tab named "My Lib Script" to be evaluated immediately. Each call to load() will cause another evaluation of the script tab.
Please note that script tabs do not share local variable scope. If you need to share data between tabs you should use global variables.