Handling Input and Output Products
This section describes the handling of products on their way into prosEO, during processing and on the way back out.
Product ingestion is the process of adding new product data from the outside to the prosEO backend storage. Types of products to ingest include, but are not limited to low-level input data (e. g. L0 data or even satellite raw data), auxiliary data or non-plannable additional output products from data processors (e. g. data which is created in unknown or varying numbers). The product ingestion process is started by an "external" client including prosEO's own Command Line Interface (CLI) or some processor wrappers. For ingestion a JSON-formatted metadata file is to be prepared, which holds all the metadata to be stored in the prosEO database alongside the product itself. The JSON structure contains an array of objects, each with the following fields (only most relevant listed):
-
id: The product database ID (only if an existing product is to be updated), -
uuid: A product UUID, if keeping an externally defined UUID is essential (not recommended, as it prevents the same product being ingested into different missions), -
missionCode: The code of the mission to ingest the products into, -
productClass: Product type of the Product class this products instantiates, -
fileClass: File class from the set defined for the enclosing mission (optional), -
mode: Processing mode from the set defined for the enclosing mission (mainly if the product is generated by this mission), -
productQuality: Indicator for the suitability of this product for general use (NOMINAL,EXPERIMENTAL,TEST; optional, defaultNOMINAL), -
sensingStartTime/sensingStopTime: Sensing start and stop times in orbit format (YYYY-MM-DDThh:mm:ss.SSSSSS), -
generationTime: Product generation time in orbit format (YYYY-MM-DDThh:mm:ss.SSSSSS), -
productionType: Type of production process generating this product (SYSTEMATIC,ON_DEMAND_DEFAULT,ON_DEMAND_NON_DEFAULT) -
orbit: Orbit relationship of this product, if any, consisting of:-
spacecraftCode: The code of the spacecraft, -
orbitNumber: The number of the orbit as stored in the metadata database (orbit data must exist)
-
-
parameters: A collection of mission-specific parameters for this product, each consisting of:-
key: The parameter name, -
parameterType: The type of the parameter (one ofSTRING,INTEGER,BOOLEAN,DOUBLE,INSTANT), -
paramterValue: The value to set,
-
-
sourceStorageType: The type of storage to ingest the data from (eitherPOSIX[most used] orS3), -
mountPoint: The S3/POSIX mount point of the storage system to ingest from (as configured in the Storage Manager), -
filePath: The S3/POSIX path to the product files (relative tomountPoint), -
productFileName; File name of the main product file, -
auxFileNames: Array of names for auxiliary files being part of the product, -
fileSize: The size of the primary product file in bytes, -
checksum: Checksum value for the primary product file (computed by MD5 algorithm; case-sensitive), -
checksumTime: Checksum generation time in orbit format (YYYY-MM-DDThh:mm:ss.SSSSSS).
A simple metadata file as used in the prosEO sample test data might look like this:
[
{
"missionCode": "PTM",
"productClass": "L0________",
"fileClass": "OPER",
"mode": "OPER",
"productQuality": "TEST",
"sensingStartTime": "2019-11-04T09:00:00.000000",
"sensingStopTime": "2019-11-04T09:45:00.000000",
"generationTime": "2019-11-04T12:00:00.000000",
"parameters": [
{
"key": "revision",
"parameterType": "INTEGER",
"parameterValue": "1"
}
],
"sourceStorageType": "S3",
"mountPoint": "s3://proseo-val-main",
"filePath": "integration-test/testdata",
"productFileName": "PTM_L0_20191104090000_20191104094500_20191104120000.RAW",
"auxFileNames": [],
"fileSize": 84,
"checksum": "50545d8ad8486dd9297014cf2e769f71",
"checksumTime": "2019-11-04T12:00:10.000000"
}
]
The diagram below shows the sequence of events during an ingestion process:
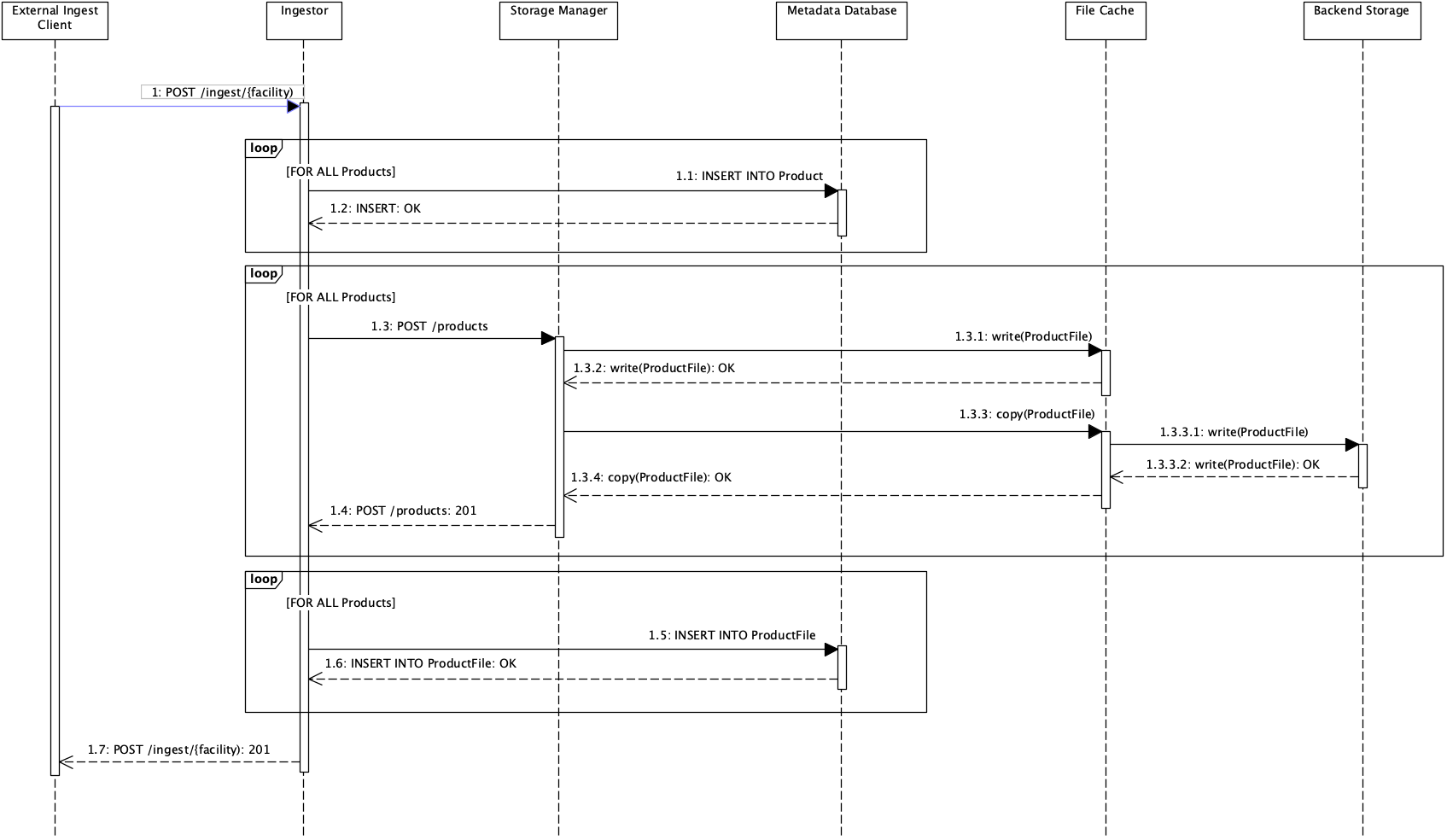
The process steps (excluding responses) are:
-
1: Send the ingestion request to the prosEO Ingestor component with a body as shown above toPOST https://<proseEO brain host>:<Ingestor port>/proseo/ingestor/v1/ingest/<processing facility name> -
1.1: Ingestor prepares the product metadata, -
1.3: Ingestor instructs the Storage Manager to copy the products from the input file path to the file cache and then to the backend storage, -
1.5: Ingestor updates the product metadata with the actual paths to the product files in the backend storage, -
1.7: Ingestor returns the metadata of the ingested products with addition of the product files created during the process.
If the initial request contains the query parameter copyFiles=false, step 1.3 is omitted and the input file paths are taken as the backend file paths. It is in the caller's responsibility to ensure that the product files stay at the given location as long as a metadata entry points to them.
During the processing of new output products a rather complex interaction between Production Planner, Processor Wrapper, Storage Manager, Ingestor and the storage components unfolds as shown below.
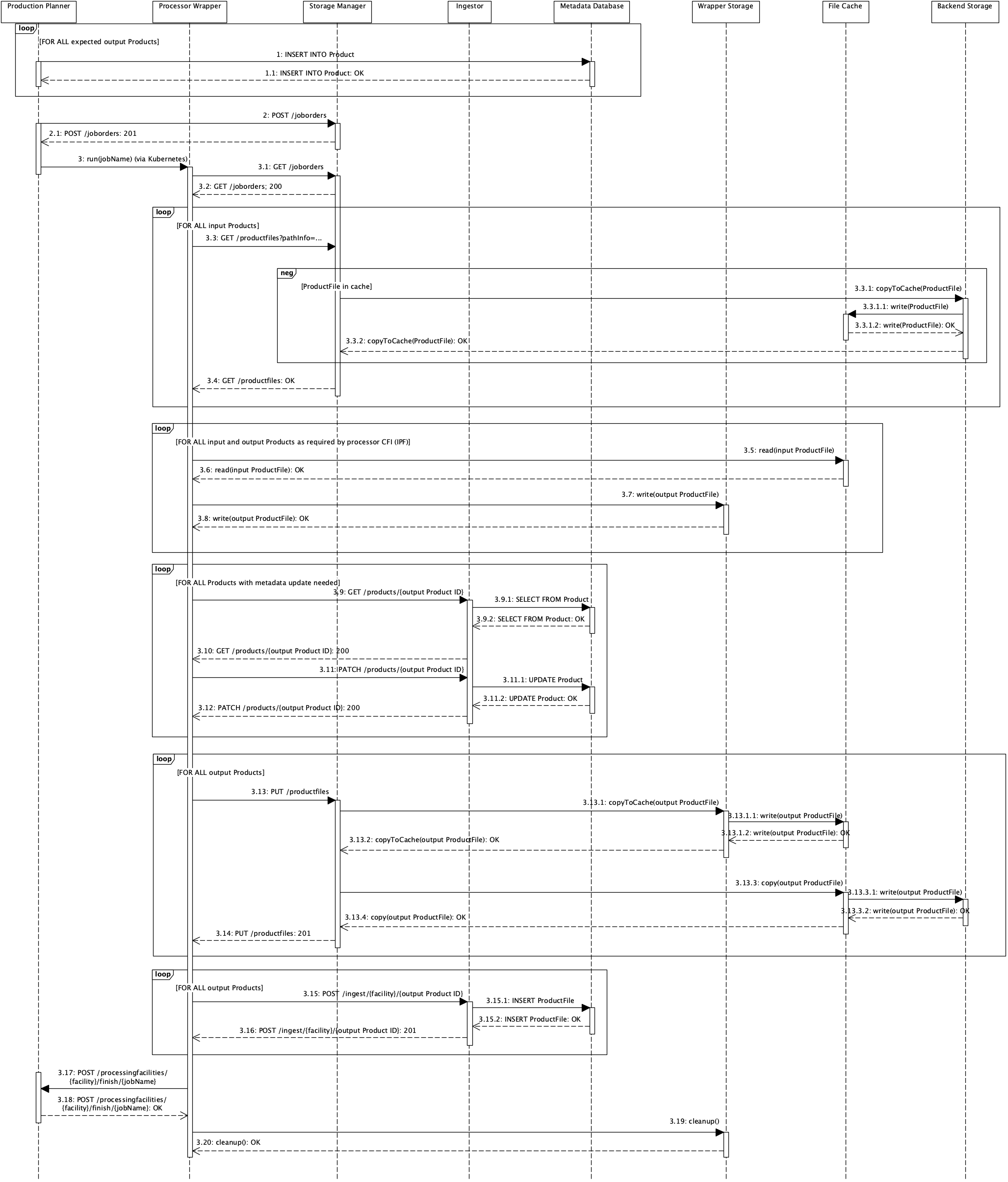
The main process steps are:
-
1: The Production Planner creates "empty shells" for the expected output products to determine their future database ID, -
2: The Production Planner sends the Job Order file to the Storage Manager, which stores it in the backend storage (not shown), -
3: The Production Planner starts the Processor Wrapper via the Kubernetes scheduler, -
3.1: The Processor Wrapper retrieves the Job Order file from the Storage Manager, -
3.3: The Processor Wrapper loops through all input files in the Job Order file and requests a product download from the Storage Manager, who provides them in a storage component accessible for the Processor Wrapper (the file cache), -
3.5/3.7: The Processor Wrapper reads the input files (3.5) from the file cache (which is read-only for the Wrapper), computes the output products and stores them (3.7) in a storage component accessible for the Storage Manager (the Wrapper Storage). -
3.9/3.11: As some or all of the output products may need updates to their metadata for information only known (immediately) after processing, the Processor Wrapper requests the original data from the Ingestor (3.9) and updates them with the current information (3.11). Additionally the Processor Wrapper may need to ingest output files not planned in the Job Order file to the Ingestor as shown above (not shown here), -
3.13: The Processor Wrapper loops through all output files in the Job Order file and requests a product upload to the Storage Manager, who copies them to the file cache and then to the backend storage and returns the file paths in the backend storage to the Wrapper, -
3.15: The Processor Wrapper updates the file paths for all output products in the metadata database via the Ingestor, -
3.17: The Processor Wrapper reports success or failure back to the Production Planner, -
3.19: The Processor Wrapper cleans up the Wrapper Storage.
The product download process comes in two flavours, either via prosEO's native API or via the ESA-defined PRIP API. The basic event sequence for both process variants however are the same.
The diagram below shows the sequence of events for a product download via the native API.
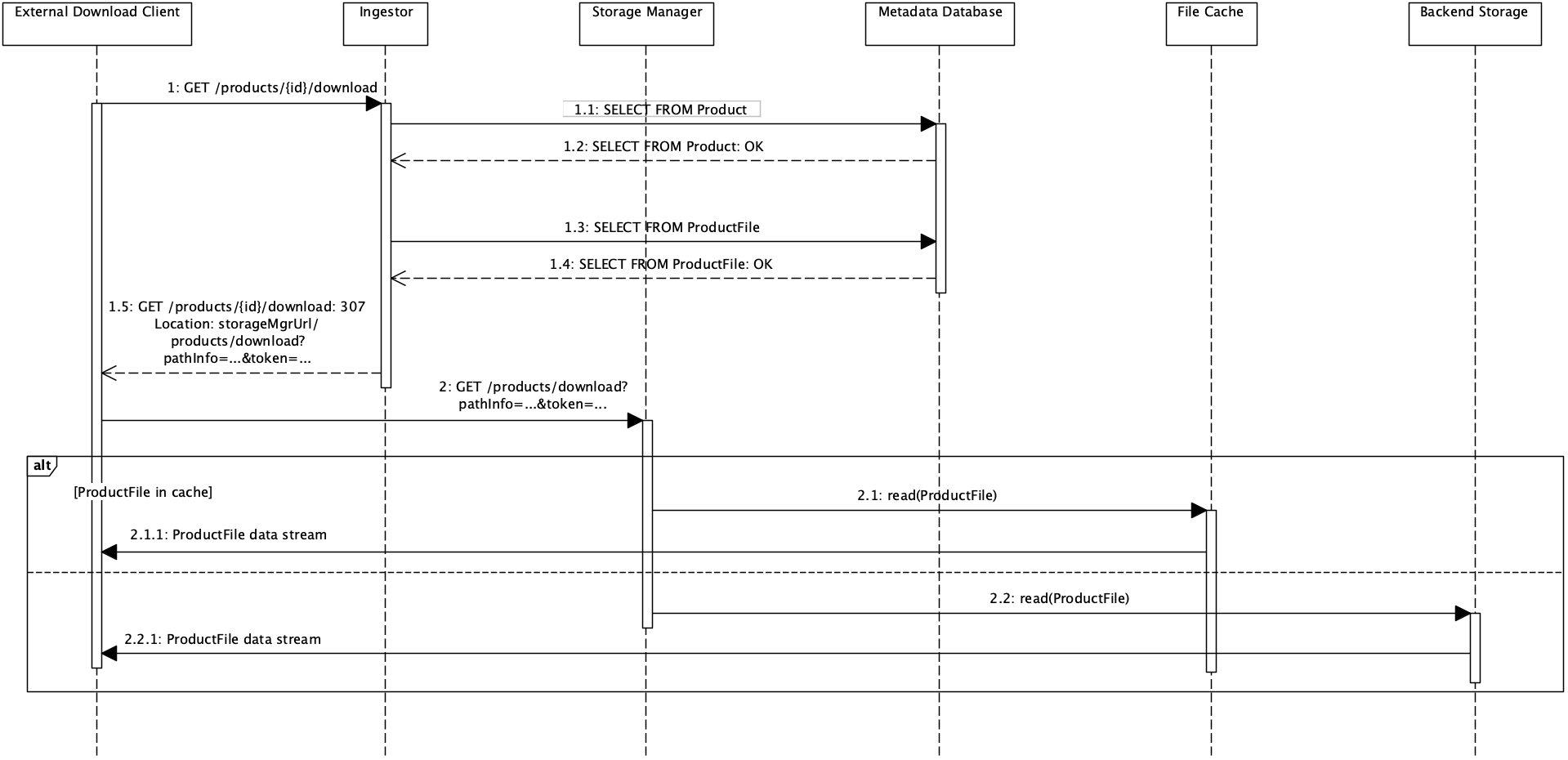
The download process consists of the following steps:
-
1: The external download client uses the product database ID to request a download from the Ingestor. The Ingestor determines the product file location and computes an authorisation token for the Storage Manager (which does not have database access and hence no means to check the user credentials). It then redirects the client to the Storage Manager. -
2: The download client follows the redirect link to the Storage Manager and authenticates itself by the token embedded in the link. The Storage Manager then provides the requested data file either from the file cache or from the backend storage.
The diagram below shows the sequence of events for a product download via the ESA-defined PRIP API.
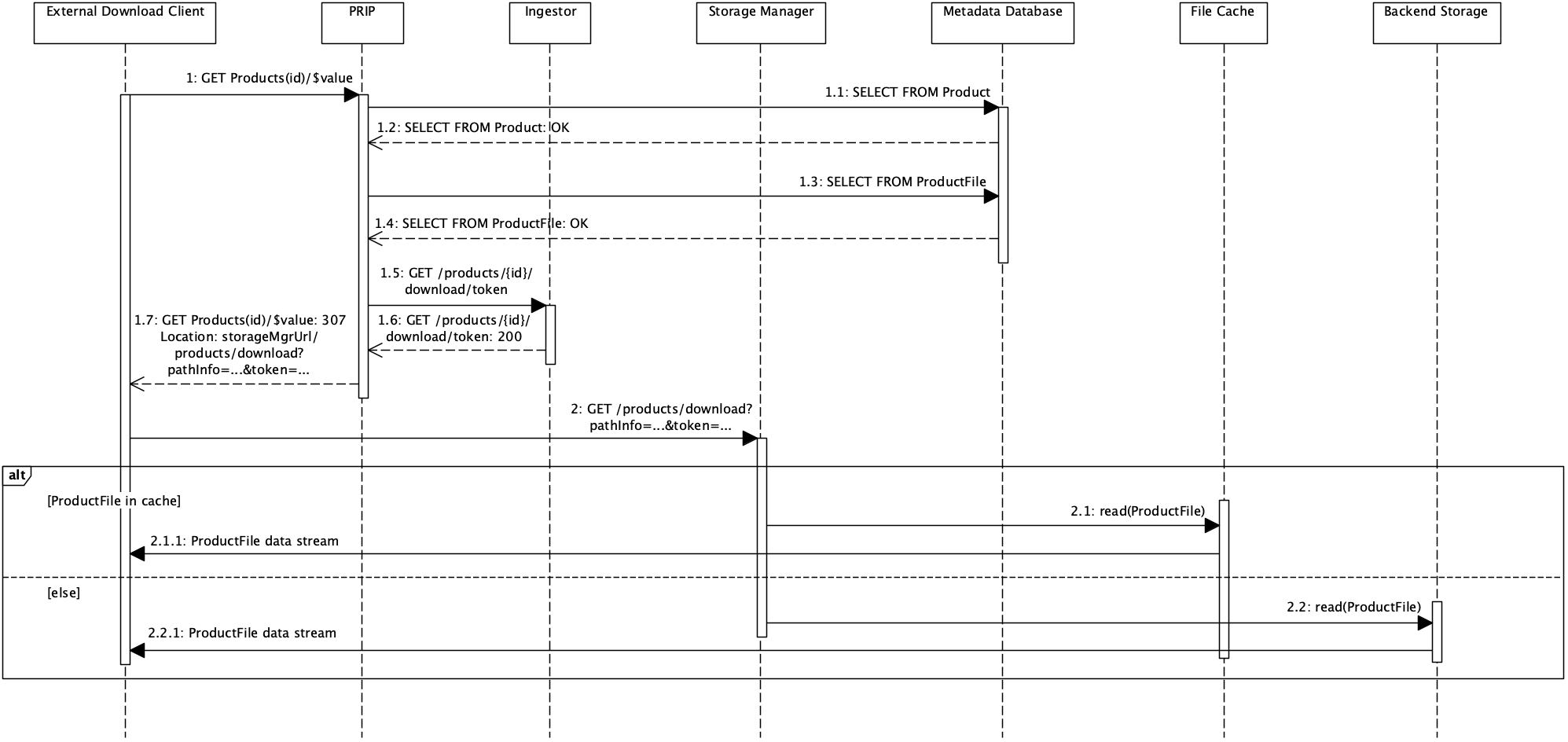
The download process consists of the following steps:
-
1: The external download client uses the product UUID to request a download from the PRIP service. The PRIP service determines the product file location and requests an authorisation token for the Storage Manager from the Ingestor. It then redirects the client to the Storage Manager. -
2: The download client follows the redirect link to the Storage Manager and authenticates itself by the token embedded in the link. The Storage Manager then provides the requested data file either from the file cache or from the backend storage.