Platform Independent Modeling with Automated Code Generation
Author: Oszkár Semeráth
The goal of this laboratory session is to gain practical experience with domain-specific modeling and template based code generation technologies. In this syllabus the demonstrating scenario is simple dataflow (activity) modeling, from which workflow implementation code is generated.
- Read this syllabus
- Read the selected sections from the linked tutorials
- Answer the questions at the end of this document
- Make sure that at least one of your previous solutions (e.g. Workflow engine with Java Generics / RabbitMQ / Thrift / etc.) is operational and ready for use
The notation of Data-flow diagrams (DFDs, basically the same as activity diagrams) are widely used for designing parallel, concurrent or asynchronous systems. It served as the inspiration for more advanced modeling notions such as UML Activity Diagrams. An example DFD specification of the Document Similarity Estimation algorithm is visible below.

A DFD consists of the following elements:
-
Data transformation nodes, which transform inputs to output. For example, the Tokenize process transforms Strings to Lists of Strings. It is important to note that a node type may have multiple instances in a diagram, for example there are two
Tokenizernode instances in the process. - Each node has one or more uniquely named input pins, which consume input values of a specific type. For example, the Scalar Product node has two input pins called "a" and "b", each accepting Vectors. When, in the context of a process instance (document in our case), data is available for all input pins, the inputs can be processed and transformed by the Nodes. Note that data from multiple process instances shall not be mixed.
- Each node has a specified output type. For now, it is enough to consider single-output nodes.
- The input pins and the outputs are connected by dedicated channels, which forward the output of a node to the input of another node. The output of a node can be used by multiple input pins, in this case each input pin gets the output. For example, the shingles of a document are processed by two different Scalar product nodes.
- Like individual nodes, the entire workflow also has inputs and an output, to which internal nodes can be connected by channels.
For more information and theoretical background:
- either read the following tutorial slides: https://inf.mit.bme.hu/sites/default/files/materials/category/kateg%C3%B3ria/oktat%C3%A1s/bsc-t%C3%A1rgyak/rendszermodellez%C3%A9s/13/Adatfolyamhalok.pdf
- or refresh your familiarity with UML/SysML Activity Diagrams
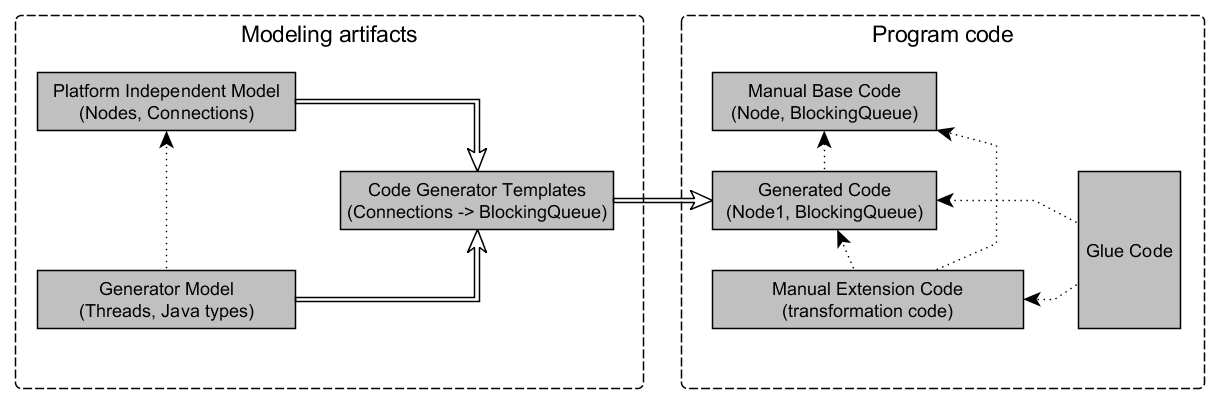
A generic code generation scenario is illustrated in the following diagram. Dependency relationships are denoted by dotted line, the double lined arrow shows the data flow of the code generation process.
-
Platform Independent Model (PIM): A generic model, that is independent of the specific technological platform used to implement the actual system. In our case, this model should consist of only data-flow specific concepts, making no assumptions on whether they are going to be realized using plain Java, Akka, etc.
-
Generator Model or Platform-Specific Model (PSM): A PSM extends the PIM with the necessary platform-specific information to generate functioning Java code. Such information might include, among others, the target location for generated code, the intended Java package, or the Java types that represent the data types mentioned in the PIM. Ideally, the same PIM could be used with multiple PSMs to generate code for different execution platforms (like Java, C#, Thrift+Java, etc.).
-
Code Generator Templates: The code generator takes models (both PIM and PSM) as an inputs, and produces textual software artifacts like system configuration or source code as output. We can imagine that the code generator transforms the PIM into code, and is parameterized by information in the PSM/generator model. Typically, the output text has a well-defined, repeating structure. For example, in a multi-threaded Java workflow realization, a generated Java source file representing a node type may be structured as follows:
- a
packagedefinition - an
importsection (which refers to the input and output types) - a
classdeclaration, containing - blocking queues for each inputs
- at least the abstract specification of the
transformfunction
- a
package ...
import ...
import ...
public abstract class Worker_A extends WorkerNode{
/**
* Input nodes
*/
BlockingQueue<Type1> input1;
BlockingQueue<Type2> input2;
/**
* override to provide actual business logic
*/
public abstract OutputType transform(Type1 input1, Type2 input2);
}The developer is able to specify the transformation using template based code generators. Using templates is a convenient and maintainable way to specify the structure of the output code.
-
Generated Code: The generated source code can be used in the same way as manually written code. However, it is highly recommended to separate the generated and manually created files, so that any generator output can be easily removed and the generator can be run again without affecting manual work. This is crucially important so that the generator itself will remain simple to implement, without the risk of destroying valuable manual code. Such separation techniques include the generation gap pattern (see later), and also appropriate file system structure (i.e. using two Java source folders,
srcandsrc-gen). -
Base Code / Runtime Library: The generated code may use or refer to previously created classes. For instance, each generated working node type may have a common superclass called
WorkerNode. In many cases it may be more convenient to implement common behaviour in superclasses rather than as code sections to be repeatedly generated. -
Extension and Glue Code: The generated code may depend on behaviour that is manually specified. For example, in the previously illustrated code the implementation of the body of the
transformmethod would be manually written. However, as mentioned before, mixing manually written code with generated code is considered bad practice. In order to tackle this challenge, the generated code must be constructed to be extensible, and manually written code must provide an appropriate extension. In some cases it is required to create additional glue code that is responsible for linking the generated code with manually developed code fragments. One common solution, though not the only one, is the generation gap pattern, where (i) the generated classes have abstract methods for manually provided behaviour, (ii) the manual code must provide separate classes that extend the generated abstract classes, and provide an implementation for those methods.
EMF is a modeling framework for developing domain-specific languages. In this laboratory, we assume that you are familiar with creating EMF metamodels. Otherwise, consult our tutorial.
Xtend is a Java dialect with direct language support for template based code generation; it is the recommended implementation technology for the code generator in this lab session. In the example below, the template generates a new class for each node in the DFD. The text between the quotation marks ''' ''' will create the source code in the generated files; more precisely, it will evaluate to a character sequence that can be saved into a source code file. What differentiates it from String literals is the possibility of escaping: Java expressions between the guillemot characters (« ») are evaluated at run-time, converted to string and concatenated to the output. Thus, for example, a computation node called "Tokenize", when run through the template Worker«worker.name», will generate the WorkerTokenize string. In context, the following Xtend method will generate a character sequence (that happens to be a fragment of Java code).
def genCode(WorkerNode worker) '''
public class Worker«worker.name» extends BaseWorkerNode {
// TODO xxx
}
'''There are several even more powerful constructs in Xtend to create complex templates:
- Conditionally included parts can be specified in
«IF condition» xxx «ENDIF»structures - Lists can be generated with loop expressions
«FOR element : collection SEPARATOR ", "» xxx(«element.x») «ENDFOR»
For the complete documentation, please read the short section of Xtend documentation devoted to template expressions.
- Create a platform independent (PIM) domain-specific language for defining simple data-flow diagrams. For this step, use EMF. The PIM language must:
- be able to declare (semantic names of) data types to be used, without defining the internal structure of the data type
- be able to declare computation node definitions with named input pins, without defining the internal business logic of the node
- be able to assign types to computation node input pins and outputs
- be able to define a workflow with input pins and output, that uses node definitions (possibly with multiple individual usages of a single computation node definition) and specifies channels to establish communication between computation node and workflow-level inputs/outputs
- Create a PSM/generator model language that cross-references elements of the PIM language, in order to specify how DFDs shall be mapped to a selected implementation platform of your choice (from one of the previous lab sessions; choosing the Java-based generic workflow engine is recommended but not mandatory). For instance, the generator model must link the data types used in the DFD to actual, pre-defined types of the implementation platform (e.g. Java classes for the generic workflow engine, or predefined structs in case of Thrift).
- Create a template-based code generator program in Xtend that transforms a DFD to code that runs on the selected platform, parameterized by the PSM. Important: make sure that the generated artifacts are usable with as little manual coding as possible. Only specify manually information that is not expressed in the model, i.e. business logic of each node.
- In order to demonstrate the independence of the approach from any computation task, create instance models for two case studies (one PIM and PSM model each), namely the running example text similarity estimating process, as well as the alternative "degree of diversity" computation workflow.
- Generate the platform-specific workflow implementation code for both computation tasks. Manually implement the necessary non-generated extensions (datatypes, business logic), as well as glue code to fit the test harness.
- Demonstrate that the obtained solutions to both tasks are operational. Run the similarity estimation tests to demonstrate that they work correctly.
- Ensure that the re-generation of derived artifacts is non-destructive towards manually written code. Use e.g. the generation gap pattern.
- In order to demonstrate the independence of the approach from any platform, develop an additional PSM language and associated code generator for a second platform of your choice.
- What are the most important elements making up a simple data-flow diagram?
- Create a data-flow diagram that compares the number of words in two
Stringinputs. Build your diagram from the following nodes:-
Tokenize: transforms
Strings toLists of Stringby splitting the document to words. -
Compare: compares two
Listsaandb, and decides whetherahas fewer elements thanb.
-
Tokenize: transforms
- What is the difference between the platform-independent model and the generator model?
- Why is it useful to separate manually written code from generated code?
- What is the generation gap pattern?
- How do you create an conditional part in Xtend templates? Create a template, that gets a
Stringparameter calledname, and- if it is not
nullwrites the value ofname, - but if
nameis null, then it writes"Unknown".
- if it is not
- How do you create iterations in Xtend templates? Create a template that gets a list of
Strings, and the output is a concatenation of the elements of the list separated by commas (,).