AutoMQ with Apache Flink: Build Open Source Streaming Platform
Apache Flink is a well-established stream processing engine, extensively applied in event-driven and mixed batch-streaming environments. AutoMQ is a highly scalable, cloud-native version of Kafka that has redesigned the storage layer for optimal cloud-native integration, resulting in cost reductions over ten times and improved scalability. With AutoMQ's complete Kafka compatibility, it effortlessly integrates with existing Kafka ecosystem tools to facilitate data reading and writing with Flink. This article will illustrate, using a WordCount example, how Flink can extract data from an AutoMQ Topic, analyze it, and then write the results back to AutoMQ.
This document references Flink version v1.19.0. Initially, consult the Flink First Step official documentation to set up a v1.19.0 Flink service.
Refer to the AutoMQ Quick Start documentation to deploy an AutoMQ cluster locally. The version of AutoMQ utilized in this example is v1.0.4
Create a topic named "to-flink" to store data designated for import into Flink for analysis and processing.
### The default port for AutoMQ installed locally is 9094.
bin/kafka-topics.sh --create --topic to-flink --bootstrap-server localhost:9094
Utilize the command-line tool to submit a batch of data for a word count calculation:
bin/kafka-console-producer.sh --topic to-flink --bootstrap-server localhost:9094
Here's the data you will input, and once the entry is complete, exit the producer by pressing Ctrl+C:
apple
apple
banana
banana
banana
cherry
cherry
pear
pear
pear
lemon
lemon
mango
mango
mango
We anticipate the following outcomes from the Flink analysis:
apple 2
banana 3
cherry 2
pear 3
lemon 2
mango 3
Once the data submission is finished, attempt to consume the data to verify it was successfully written:
bin/kafka-console-consumer.sh --topic to-flink --from-beginning --bootstrap-server localhost:9094
Establish a topic to gather results processed by Flink
bin/kafka-topics.sh --create --topic from-flink --bootstrap-server localhost:9094
Leveraging AutoMQ's seamless Kafka compatibility, we can directly employ the Kafka Connector offered by Flink for writing source and sink code, enabling the loading of data from AutoMQ's Topic.
....
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.19.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>1.19.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>1.19.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>1.17.2</version>
</dependency>
....
<!-- shade 插件支持下build jar -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.5.2</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<finalName>automq-wordcount-flink-job</finalName>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.automq.example.flink.WordCount</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
The following Java code defines an AutoMQ source and sink using KafkaSource and KafkaSink, respectively. It starts by reading a "fruit list" test dataset from the topic "to-flink." A DataStream is then created to perform the WordCount computation, and the results are subsequently sent to the AutoMQ topic "from-flink."
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.automq.example.flink.WordCount;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
*/***
* * This is a re-write of the Apache Flink WordCount example using Kafka connectors.*
* * Find the reference example at https://github.com/redpanda-data/flink-kafka-examples/blob/main/src/main/java/io/redpanda/examples/WordCount.java*
* */*
public class WordCount {
final static String *TO_FLINK_TOPIC_NAME *= "to-flink";
final static String *FROM_FLINK_TOPIC_NAME *= "from-flink";
final static String *FLINK_JOB_NAME *= "WordCount";
public static void main(String[] args) throws Exception {
// Use your AutoMQ cluster's bootstrap servers here
final String bootstrapServers = args.length > 0 ? args[0] : "localhost:9094";
// Set up the streaming execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.*getExecutionEnvironment*();
KafkaSource<String> source = KafkaSource.<String>*builder*()
.setBootstrapServers(bootstrapServers)
.setTopics(*TO_FLINK_TOPIC_NAME*)
.setGroupId("automq-example-group")
.setStartingOffsets(OffsetsInitializer.*earliest*())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
KafkaRecordSerializationSchema<String> serializer = KafkaRecordSerializationSchema.*builder*()
.setValueSerializationSchema(new SimpleStringSchema())
.setTopic(*FROM_FLINK_TOPIC_NAME*)
.build();
KafkaSink<String> sink = KafkaSink.<String>*builder*()
.setBootstrapServers(bootstrapServers)
.setRecordSerializer(serializer)
.build();
DataStream<String> text = env.fromSource(source, WatermarkStrategy.*noWatermarks*(), "AutoMQ Source");
// Split up the lines in pairs (2-tuples) containing: (word,1)
DataStream<String> counts = text.flatMap(new Tokenizer())
// Group by the tuple field "0" and sum up tuple field "1"
.keyBy(value -> value.f0)
.sum(1)
.flatMap(new Reducer());
// Add the sink to so results
// are written to the outputTopic
counts.sinkTo(sink);
// Execute program
env.execute(*FLINK_JOB_NAME*);
}
*/***
* * Implements the string tokenizer that splits sentences into words as a user-defined*
* * FlatMapFunction. The function takes a line (String) and splits it into multiple pairs in the*
* * form of "(word,1)" ({@code Tuple2<String, Integer>}).*
* */*
* *public static final class Tokenizer
implements
FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
// Normalize and split the line
String[] tokens = value.toLowerCase().split("\\W+");
// Emit the pairs
for (String token : tokens) {
if (token.length() > 0) {
out.collect(new Tuple2<>(token, 1));
}
}
}
}
// Implements a simple reducer using FlatMap to
// reduce the Tuple2 into a single string for
// writing to kafka topics
public static final class Reducer
implements
FlatMapFunction<Tuple2<String, Integer>, String> {
@Override
public void flatMap(Tuple2<String, Integer> value, Collector<String> out) {
// Convert the pairs to a string
// for easy writing to Kafka Topic
String count = value.f0 + " " + value.f1;
out.collect(count);
}
}
}After executing a mvn build, the resulting file is an automq-wordcount-flink-job.jar, which is the job that needs to be submitted to Flink.
Execute the following command to submit the task jar to Flink, and monitor the console to see that 15 pieces of data have been received and processed.
./bin/flink run automq-wordcount-flink-job.jar
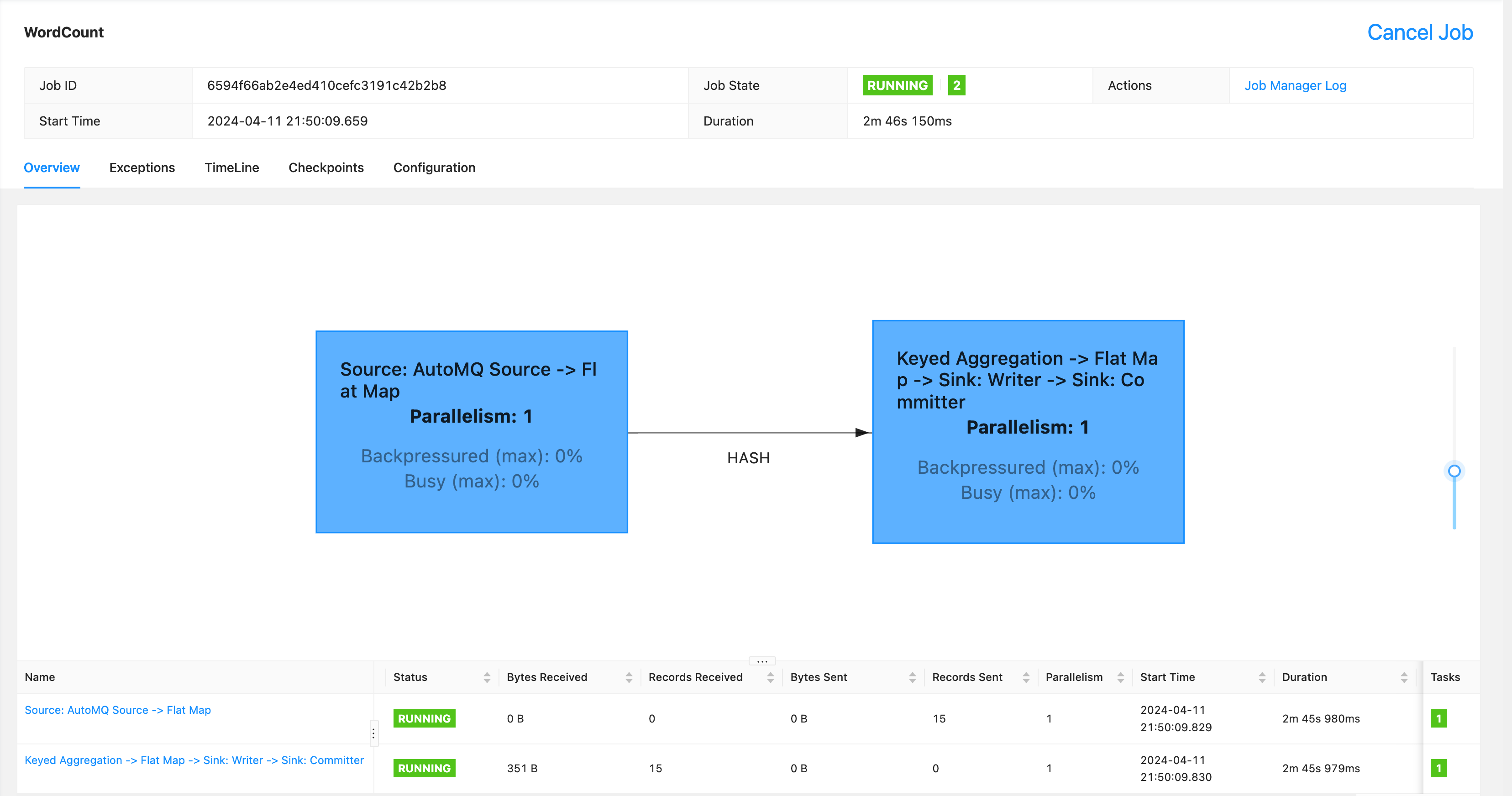
Use the Kafka bin tools extracted from AutoMQ to consume data from "from-flink" and review the results:
bin/kafka-console-consumer.sh --topic from-flink --from-beginning --bootstrap-server localhost:9094
The output is displayed as follows: Since it processes on a streaming basis without the use of watermarks and window calculations, the word count results are printed each time they are computed.
apple 1
apple 2
banana 1
banana 2
banana 3
cherry 1
cherry 2
pear 1
pear 2
pear 3
lemon 1
lemon 2
mango 1
mango 2
mango 3
We then write 5 more records to the to-flink Topic and monitor the streaming outcomes:
bin/kafka-console-producer.sh --topic to-flink --bootstrap-server localhost:9094
The data written includes:
apple
banana
cherry
pear
lemon
Subsequently, we can view the accurate word count results recently fetched from the from-flink Topic
apple 3
banana 4
cherry 3
pear 4
lemon 3
On the console, it is evident that 20 records have been accurately received and processed:

This article illustrates how AutoMQ seamlessly integrates with Flink to perform a Word Count analysis. For additional configuration and usage details on the Kafka Connector, please consult the Flink official documentation Apache Kafka Connector.