Introducing AutoMQ Table Topic: Seamless Integration with S3 Tables and Iceberg
Another title: Beyond shared-storage: Unifying Streaming and Analytics with AutoMQ Table Topic in Apache Iceberg
Author: Xinyu Zhou, Co-founder & CTO at AutoMQ
Since its announcement in the second half of 2023, AutoMQ has successfully transformed Apache Kafka from a Shared Nothing architecture to a Shared Storage architecture. This evolution leverages the scalability, elasticity, and cost-efficiency of cloud computing, resulting in significant cost savings of at least 50% for major companies like JD.com (JD.US), Zhihu (ZH.US), REDnote, POIZON, and Geely Auto (0175.HK). The advantages of Shared Storage architecture are clear and impactful.
However, are the benefits of shared storage limited to cost savings? In today's data-intensive software landscape, data is ultimately stored in object storage. Despite this convergence at the storage layer, disparate systems often struggle with data interoperability due to inconsistent storage formats. This necessitates complex ETL processes to break down data silos and harness the full potential of data at scale.
Fortunately, Apache Iceberg has emerged as the de facto standard for table formats, providing a unified format for data stored on S3. This standardization enables seamless data interaction and usage across different systems. Today, we stand on the brink of a new paradigm shift from Shared Storage to Shared Data.
In this article, we explore how AutoMQ Table Topic, in conjunction with AWS S3 Table and Apache Iceberg, is driving this transformation. By unifying streaming and analytics, we can unlock unprecedented efficiencies and capabilities in data management.
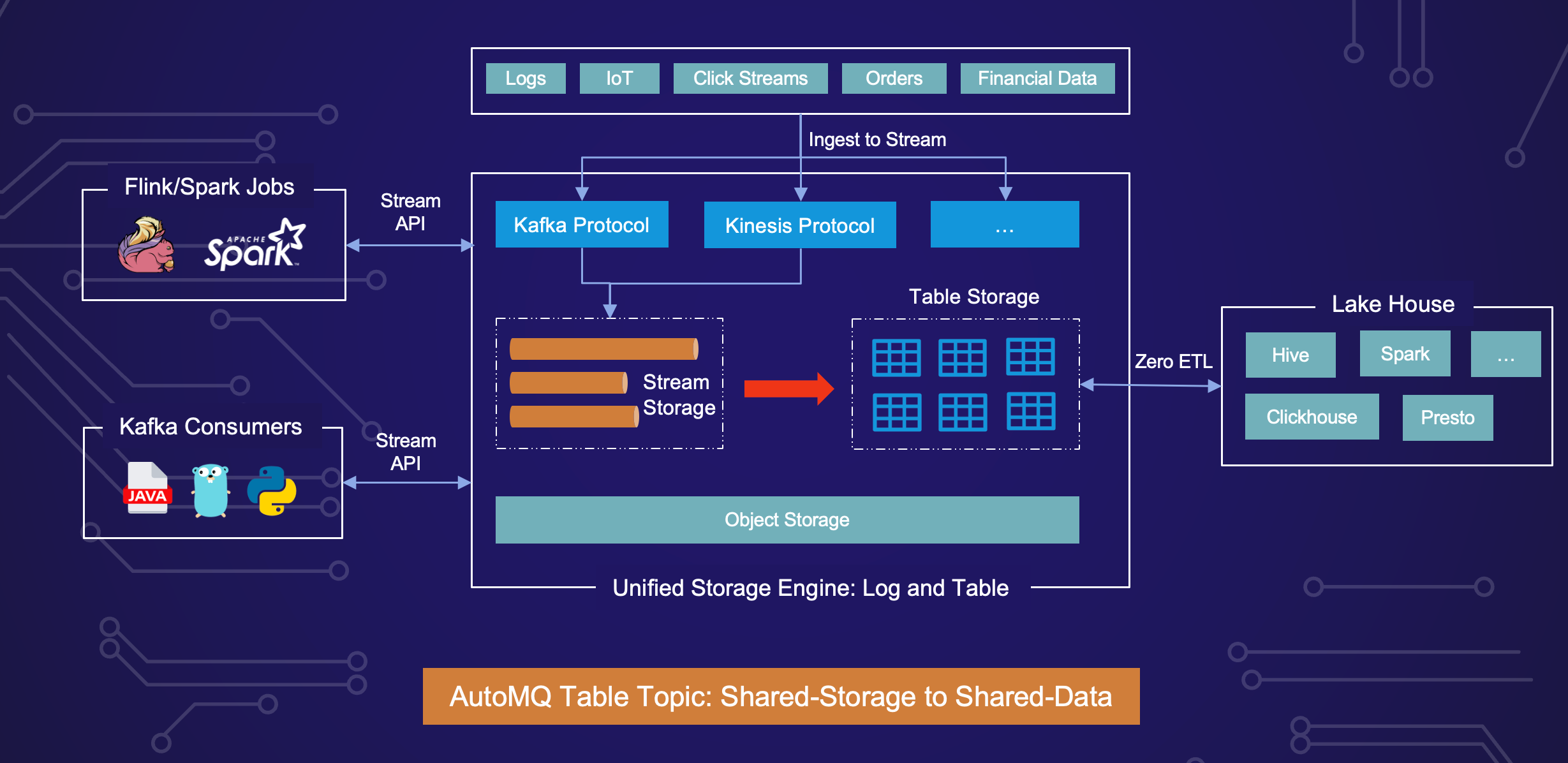
The landscape of data-intensive systems has significantly transformed over the years, evolving through various architectural paradigms to meet growing data processing and management demands. This evolution can be broadly categorized into three key stages: shared-nothing, shared-storage, and shared-data architectures.
Many on-premise data management systems were designed using a shared-nothing architecture about a decade ago. In this setup, each node operates independently with its own memory and disk, eliminating any single point of contention. This design was particularly suited for on-premise environments where scalability and fault isolation were critical.
The primary advantage of shared-nothing systems is their ability to scale horizontally by adding more nodes to handle increased data loads. However, ensuring data consistency and coordinating operations across multiple nodes can become complex and inefficient, especially as the system scales.
As data volumes grew, the limitations of shared-nothing architecture became apparent, leading to the rise of shared-storage systems. The maturity of cloud-based object storage, such as Amazon S3, Azure Blob Storage, and Google Cloud Storage, has been pivotal in this evolution.
Object storage offers immense scalability, durability, and cost efficiency. It automatically replicates data across multiple locations, ensuring high availability, and can scale virtually without limits. Its lower cost per gigabyte compared to traditional storage solutions makes it an economical choice for large-scale data storage.
These advantages have driven foundational software across various industries to evolve based on shared-storage architectures. For instance, streaming platforms like AutoMQ and WarpStream, as well as observability tools such as Grafana's Tempo, Loki, and Mimir, are built on object storage. This allows them to efficiently manage and process vast amounts of data, providing robust, scalable, and cost-effective solutions for modern data-intensive applications.
Shared-data architecture is the latest evolution, addressing the limitations of both shared-nothing and shared-storage architectures. Shared-data systems leverage distributed storage and processing frameworks to provide immediate access to data as it is generated, enabling real-time analytics and decision-making.
One key innovation driving this shift is the integration of advanced data formats like Apache Iceberg, which supports schema evolution, partitioning, and time travel, making it ideal for managing large-scale data lakes. Systems supporting Iceberg can seamlessly handle both batch and stream data, breaking down the barriers between real-time and historical data processing.
AutoMQ exemplifies the shared-data architecture with its Table Topic feature, which natively supports Apache Iceberg. This integration allows stream data to be ingested directly into the data lake and transformed into structured, queryable tables in real time. The Table Topic feature bridges the gap between batch and stream processing, enabling enterprises to analyze and act on data as it is generated.
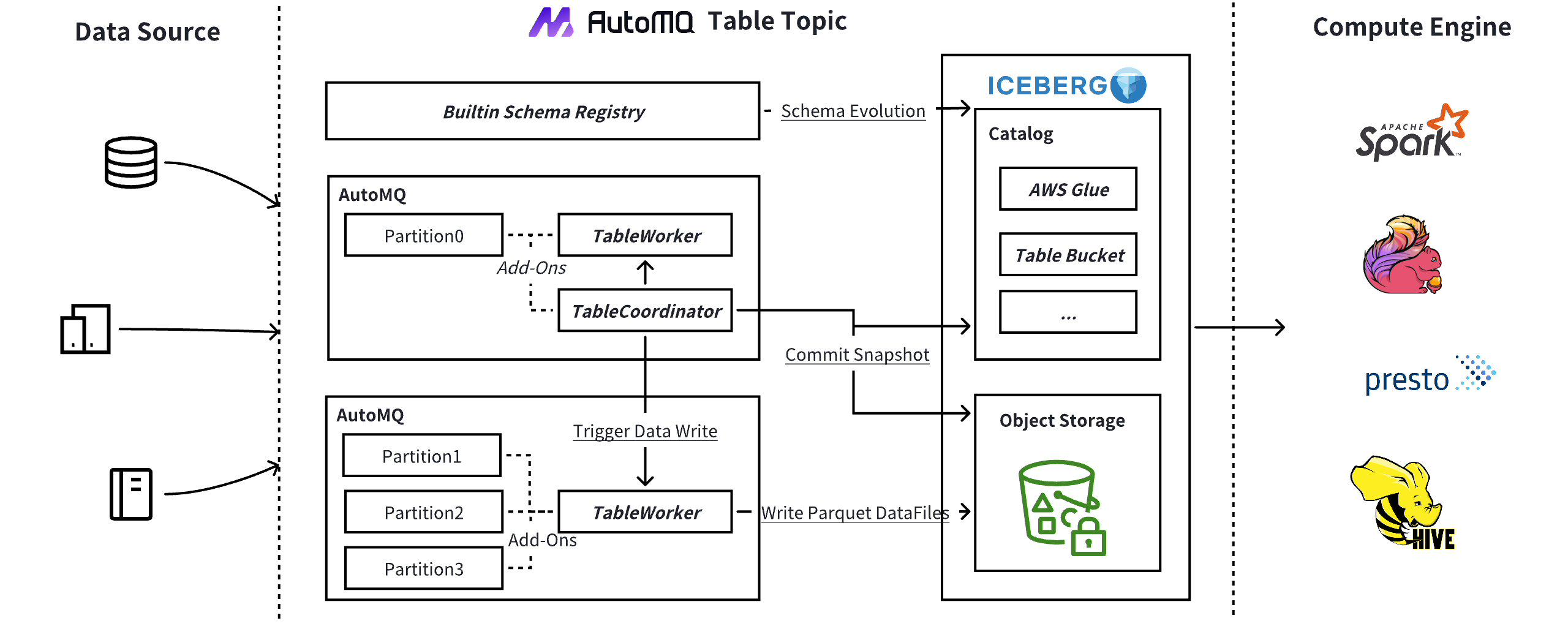
Table Topic is an integral feature built into AutoMQ, leveraging the simplicity of AutoMQ's core architecture without requiring additional nodes. This aligns perfectly with Amazon CTO Werner Vogels' concept of embracing "Simplexity". Table Topic comprises several submodules:
-
Schema Management : It includes a built-in Kafka Schema Registry. Kafka clients can directly use the Schema Registry endpoint, which automatically synchronizes Kafka schemas with Iceberg's Catalog Service, such as AWS Glue, AWS Table Bucket, and Iceberg Rest Catalog Service. Users do not need to worry about schema changes, as Table Topic supports automatic schema evolution.
-
Table Coordinator : Each topic has a Table Coordinator, centralizing the coordination of all nodes for Iceberg Snapshot submissions. This significantly reduces commit frequency, avoiding conflicts and potential performance impacts. Periodically, the system's topic
__automq.table.controlbroadcastsCommitRequestmessages to Workers. After workers upload data files, the coordinator executes the commit and submits the data to the catalog. -
Table Worker : Each AutoMQ node has an embedded Table Worker responsible for writing data from all partitions on that node to Iceberg. By listening to
CommitRequestevents, Table Workers upload Table Topic data to Data Files.
The interval for data submission to Iceberg is configurable, allowing users to balance real-time processing and cost efficiency. It is recommended that this interval be set to a few minutes, enabling queries through Iceberg-compatible compute engines.
Here are the main advantages of Table Topic compared to using Kafka Connect for streaming data into a data lake:
-
**A single click is all you need: ** Enable AutoMQ Table Topic with a single click, and effortlessly stream data into your Iceberg table for continuous, real-time analytics.
-
Built-in Schema Registry: The built-in Kafka Schema Registry is ready to use out of the box. Table Topic leverages registered schemas to automatically create Iceberg Tables in your catalog service, such as AWS Glue, and also supports automatic schema evolution.
-
Zero ETL(Extract, Transform, Load): Traditional data lake ingestion methods often require tools like Kafka Connect or Flink as intermediaries. Table Topic eliminates this ETL pipeline, significantly reducing costs and operational complexity.
-
Auto Scaling: AutoMQ itself is a stateless and elastic architecture, allowing brokers to scale up or down seamlessly and partitions to be reassigned dynamically. Table Topic fully leverages this framework, effortlessly handling data ingestion rates from hundreds of MiB/s to several GiB/s.
-
Seamless integration with AWS S3 Tables: Table Topic seamlessly integrates with S3 Tables, harnessing their catalog service and maintenance capabilities like compaction, snapshot management, and unreferenced file removal. This integration also facilitates large-scale data analysis through AWS Athena.
In this section, we'll walk you through setting up and using AutoMQ Table Topic on AWS Marketplace. We'll focus on constructing an architecture optimized for clickstream data using AWS S3 Tables and AWS Athena. With AutoMQ, we'll ingest data directly into an S3 Table Bucket, eliminating the need for ETL, and enabling straightforward querying with Athena. Here are the steps to get started:
Tips: You can also view the complete video tutorial for table topic from Youtube.
First, navigate to the AutoMQ page on AWS Marketplace and click on the "Subscribe" button to subscribe to AutoMQ. Follow the instructions to install the latest version of AutoMQ in your VPC using the BYOC (Bring Your Own Cloud) model. Detailed instructions for this process can be found here.
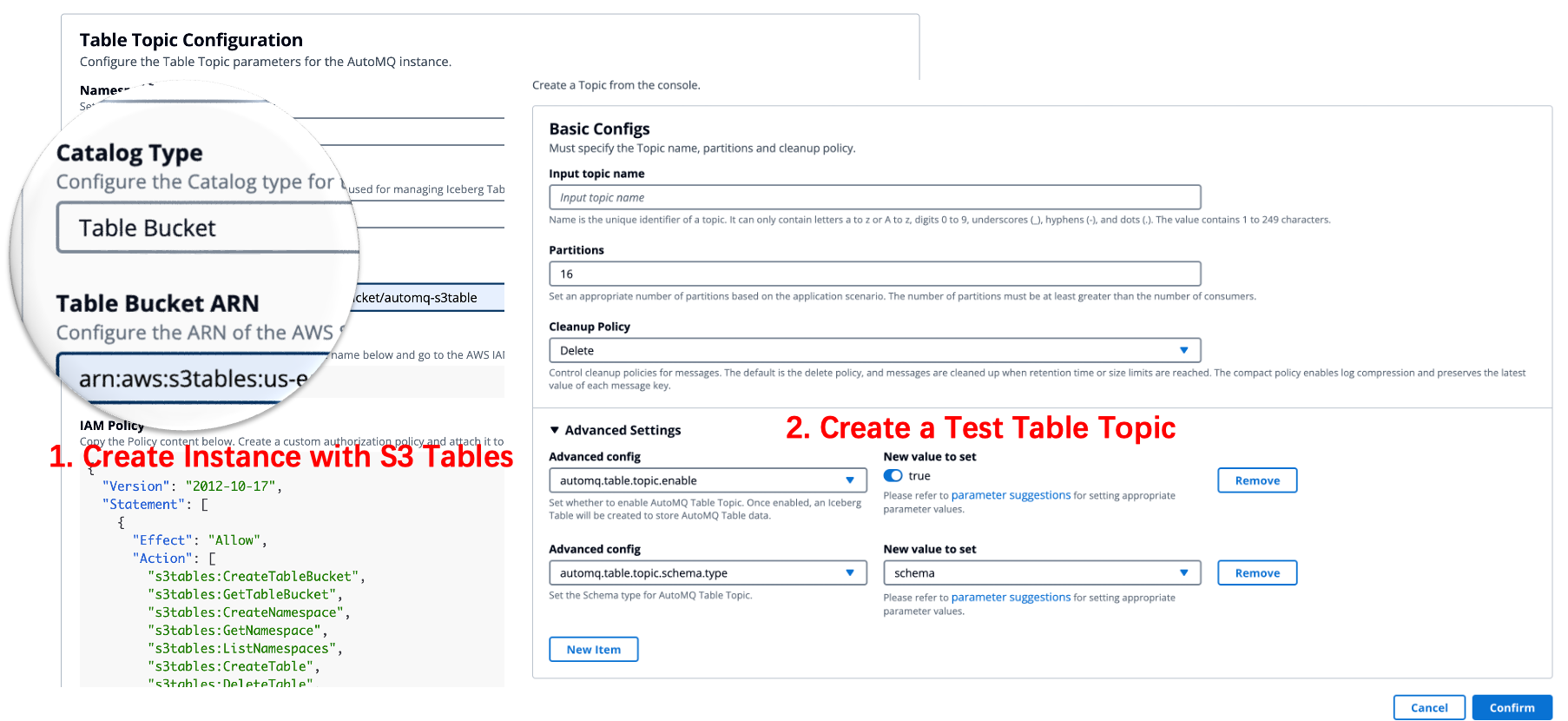
First, launch the AWS Management Console and go to the S3 service. Create a new S3 table bucket for storing your table data and record its ARN.
Then, log in to the AutoMQ BYOC Console using the provided URL and your credentials. Set up a new instance with the latest AutoMQ version, linking it to the ARN of your S3 bucket during setup.
After the instance is ready, go to the Topics section in AutoMQ BYOC, create a test topic, and activate the Table Topic feature for it.
Get the endpoints for your AutoMQ instance and Schema Registry from the AutoMQ BYOC Console. Utilize Kafka clients to link to your AutoMQ instance with these endpoints, and dispatch Clickstream data to the Table Topic you established in the prior step.
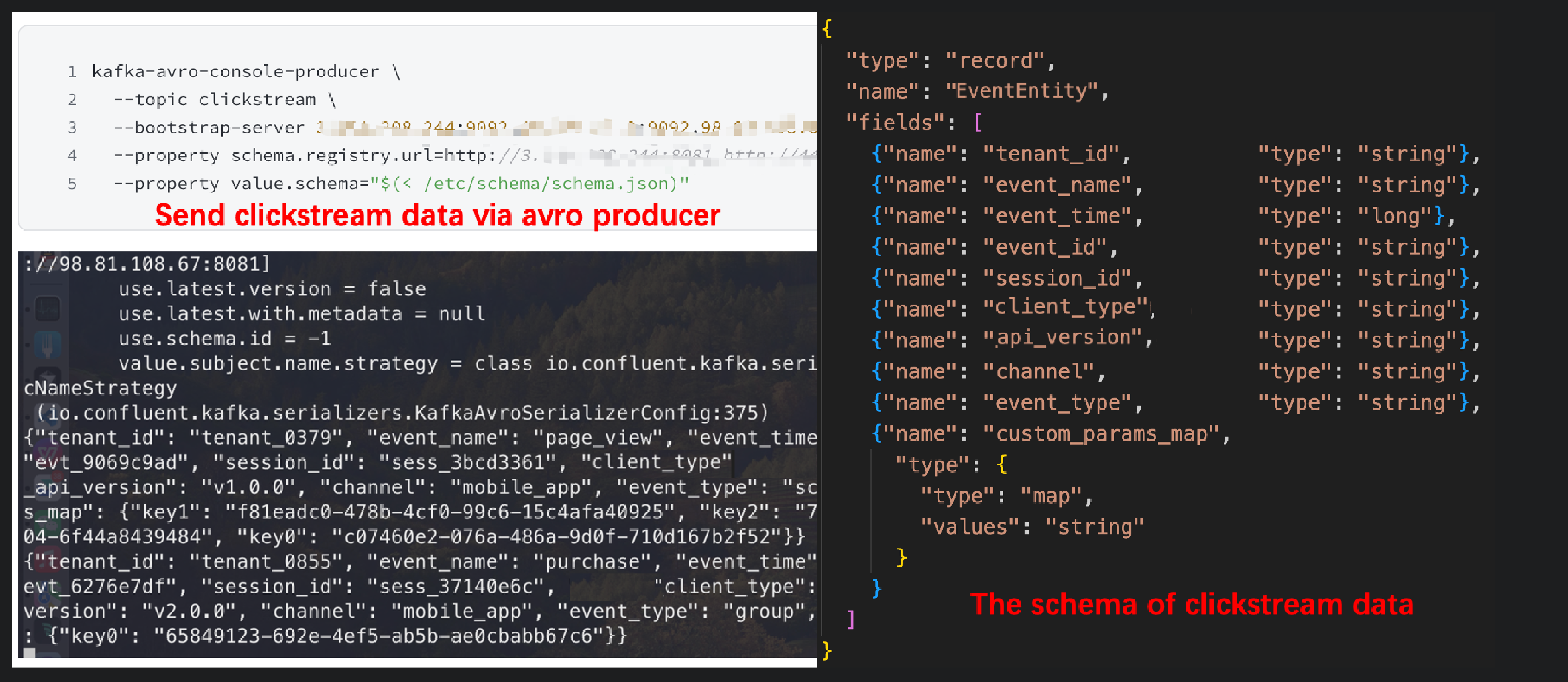
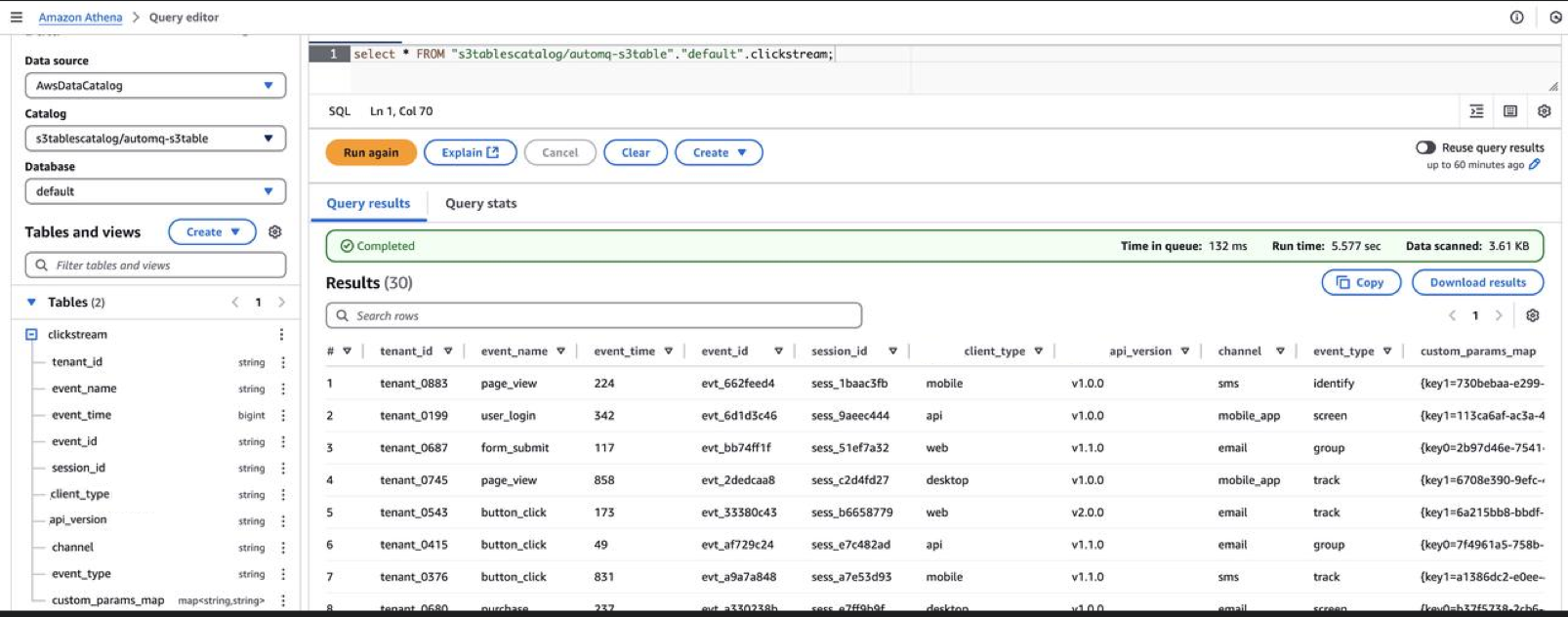
AutoMQ Table Topic will automatically create tables in your AWS S3 table bucket. To query this data, open AWS Athena in the AWS Management Console. Use Athena to query the Clickstream data stored in the tables created by AutoMQ.
In this article, we explored the seamless integration of AutoMQ Table Topic with AWS S3 Tables and Iceberg. This powerful combination simplifies data ingestion, storage, and querying, eliminating the need for complex ETL processes.
By leveraging AutoMQ and AWS services, you can efficiently manage large volumes of data and gain real-time insights with ease. This integration provides a scalable and reliable solution for your data needs.
We hope this guide has been helpful. For more information, please refer to the AutoMQ documentation. Thank you for reading!