Difference with WarpStream
AutoMQ and WarpStream both leverage object storage to store message data, and they share some architectural similarities. This article will focus on the differences and comparisons between AutoMQ and WarpStream.
WarpStream reimplements the Apache Kafka® protocol, utilizing S3 object storage to build Kafka functionalities. This architecture does not reuse any Kafka code but instead uses the WarpStream Agent component to reimplement Kafka features and APIs. Messages produced by applications are directly forwarded to S3 object storage by the Agent, which itself does not need to implement storage logic, resulting in a completely stateless architectural design.
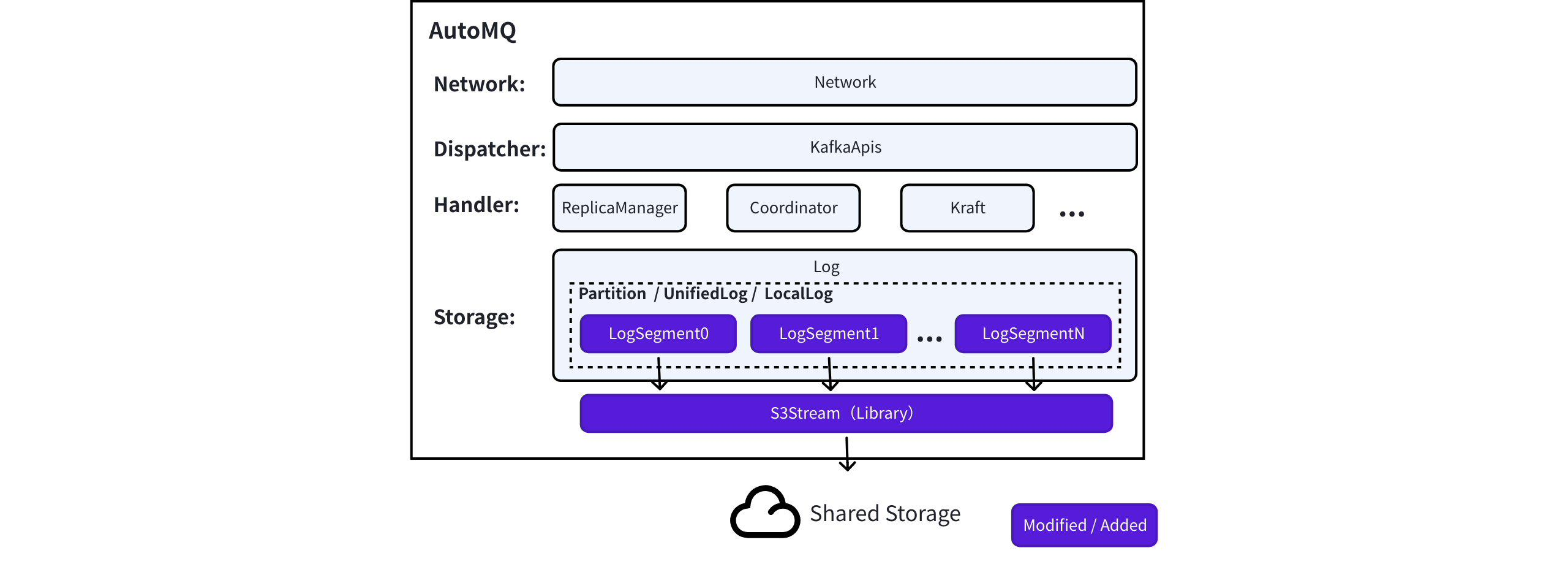
AutoMQ, on the other hand, adopts a stateless design philosophy with storage-compute separation in its technical architecture. It chooses to reuse the Apache Kafka® computation layer code, separating the storage layer originally based on local storage to remote storage based on S3 object storage. Only minimal aspects of the storage layer are replaced, maintaining the consistency of the upper-layer protocol and functional interfaces.
WarpStream Architecture
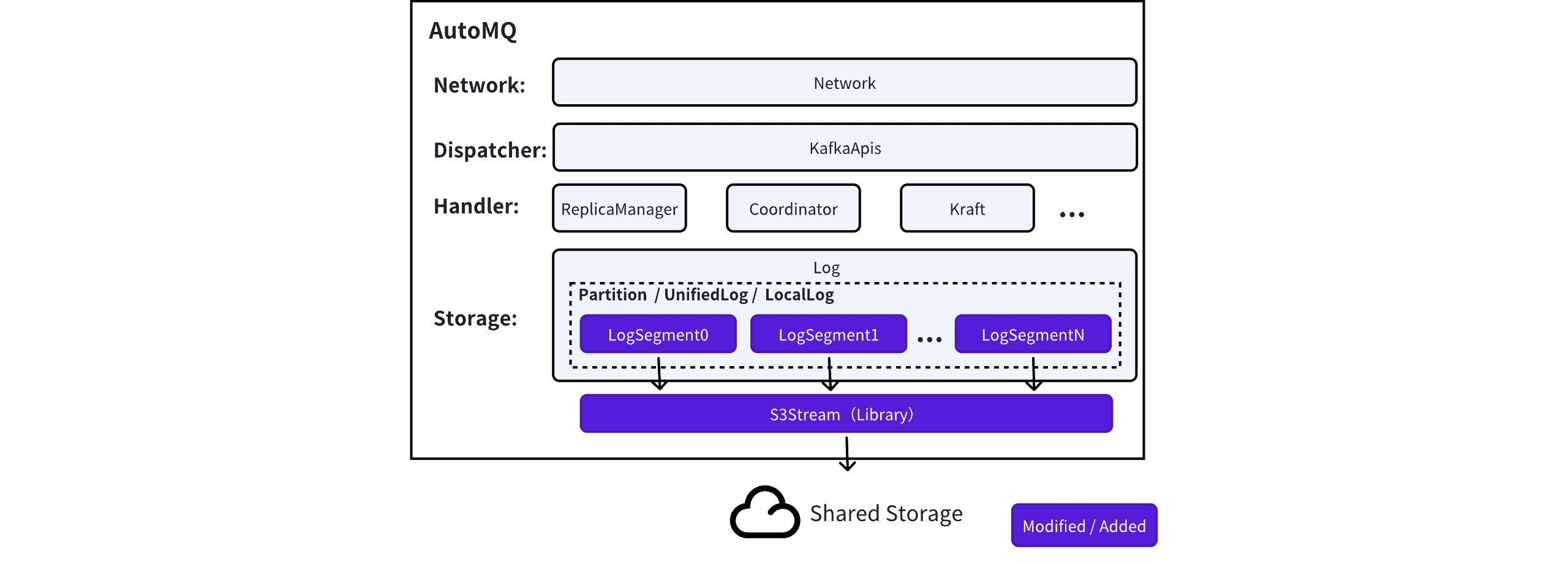
AutoMQ Architecture
WarpStream opts to reimplement the Apache Kafka® protocol and currently only supports the main APIs for producing and consuming messages. Advanced features like transactional messages and ExactlyOnce are not yet supported, and some interfaces cannot be implemented due to architectural differences. For detailed information, please refer to the reference link.
AutoMQ reuses the computation layer code of Apache Kafka, only replacing the underlying storage, which ensures full compatibility with the corresponding version of Apache Kafka. Applications using Apache Kafka can switch to AutoMQ without modifying configurations. For more details on compatibility, please refer to Compatibility with Apache Kafka▸.
WarpStream uses agent components to forward messages to object storage. Accessing S3 incurs API billing and introduces hundreds of milliseconds of call latency, so batch processing is performed in the synchronous message writing path. This results in WarpStream's P99 write latency exceeding 620ms, with an end-to-end P99 latency reaching 1.27s.
AutoMQ utilizes block storage EBS as a WAL cache in the message writing path. It returns a response once the message is written to EBS and asynchronously uploads it to object storage in the background, while using memory to quickly cache hot data, achieving millisecond-level message read and write latency.
WarpStream is a commercial closed-source project that provides a Kafka protocol-compatible service. In contrast, AutoMQ offers a fully managed cloud service and private deployment options. The private deployment can opt for the Community Edition, which provides source code. For detailed information, please refer to Licensing▸.
While both AutoMQ and WarpStream use object storage, there are differences in their architectural focus and trade-offs. The summary comparison is as follows:
|
Comparison Item |
WarpStream |
AutoMQ |
|---|---|---|
|
Architecture |
Rewrite Kafka protocol |
Aspect replacement for Kafka storage |
|
Compatibility |
Partially compatible with Apache Kafka® features |
Reuses Kafka compute layer code, fully compatible |
|
Latency |
400+ms write latency, 1-second end-to-end latency |
< 10ms read/write latency |
|
Openness |
Commercial closed-source |
Commercial + source visible |